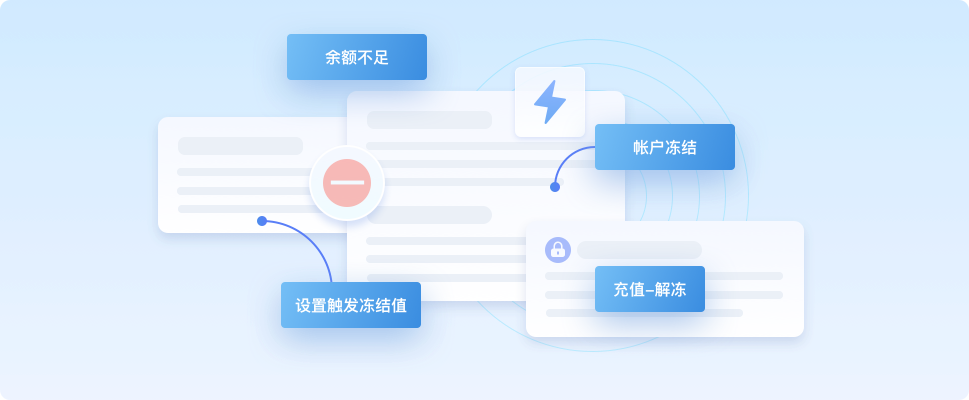
快速充值
快速充值

 自助开户
自助开户

 余额预警
余额预警
 自助管理
自助管理

大数据型实例搭载海量存储资源,具有高吞吐特点,适合 Hadoop 分布式计算、海量日志处理、分布式文件系统和大型数据仓库等吞吐密集型应用。
说明:
大数据型 D3、D2 实例的数据盘是本地硬盘,有丢失数据的风险(例如宿主机宕机时),如果您的应用不能做到数据可靠性的架构,我们强烈建议您使用可以选择云硬盘作为数据盘的实例。
大数据型 D3 实例是最新一代的大数据型实例,配备搭载高吞吐、海量存储资源,最高可搭载 94T SATA HDD 本地存储, 适合 Hadoop 分布式计算、并行数据处理等吞吐密集型业务使用。
Hadoop MapReduce/HDFS/Hive/HBase 等分布式计算。
Elasticsearch、日志处理和大型数据仓库等业务场景设计。
互联网行业、金融行业等有大数据计算与存储分析需求的行业客户,进行海量数据存储和计算的业务场景。
2.5GHz Intel® Xeon® Cascade Lake 处理器,DDR4 内存。
实例最高搭载24块4TB本地硬盘,配备最高94TB的基于 HDD 的本地存储。
单盘读顺序吞吐性能不低于190MB/s。
毫秒级读写延时。
处理器与内存配比为1:4,为大数据场景设计。
若云服务器实例已经宕机,我们会告知您并进行维修操作。
D3 实例未安装监控组件会导致平台无法对实例进行更细致的监控,若实例发生故障则将无法正常通知,可能存在高危风险。请参见 安装云服务器监控组件 完成监控组件安装。
大数据型 D3 实例可以用作包年包月实例和按量计费实例。
仅支持在私有网络中启动 D3 实例。
D3 实例不支持调整配置。
D3 实例支持购买配置,请参阅下方实例规格。
规格 | vCPU | 内存 (GB) | 网络收发包(pps)(出+入) | 连接数 | 队列数 | 内网带宽能力(Gbps)(出+入) | 主频 | 备注 |
D3.2XLARGE32 | 8 | 32 | 80万 | 25万 | 2 | 4.0 | 2.5GHz | 搭载4块3720GB SATA HDD 本地硬盘 |
D3.4XLARGE64 | 16 | 64 | 150万 | 30万 | 4 | 7.0 | 2.5GHz | 搭载8块3720GB SATA HDD 本地硬盘 |
D3.8XLARGE128 | 32 | 128 | 250万 | 60万 | 8 | 14.0 | 2.5GHz | 搭载12块3720GB SATA HDD 本地硬盘 |
D3.16XLARGE256 | 64 | 256 | 500万 | 120万 | 12 | 27.0 | 2.5GHz | 搭载24块3720GB SATA HDD 本地硬盘 |
D3.21XLARGE320 | 84 | 320 | 600万 | 160万 | 16 | 32.0 | 2.5GHz | 搭载24块3720GB SATA HDD 本地硬盘 |
云服务器ECS(Elastic Compute Service)是阿里云提供的性能卓越、稳定可靠、弹性扩展的IaaS(Infrastructure as a Service)级别云计算服务。云服务器ECS免去了您采购IT硬件的前期准备,让您像使用水、电、天然气等公共资源一样便捷、高效地使用服务器,实现计算资源的即开即用和弹性伸缩。阿里云ECS持续提供创新型服务器,解决多种业务需求,助力您的业务发展。
云服务器提供多种经过优化,适用于不同使用案例的实例类型以供选择。实例类型由 CPU、内存、存储和网络容量组成不同的组合,可让您灵活地为您的应用程序选择适当的资源组合。每种实例类型都包括一种或多种实例大小,从而使您能够扩展资源以满足目标工作负载的要求。