本文介绍了如何在GPU实例上基于NGC环境使用RAPIDS加速库,加速数据科学和机器学习任务,提高计算资源的使用效率。
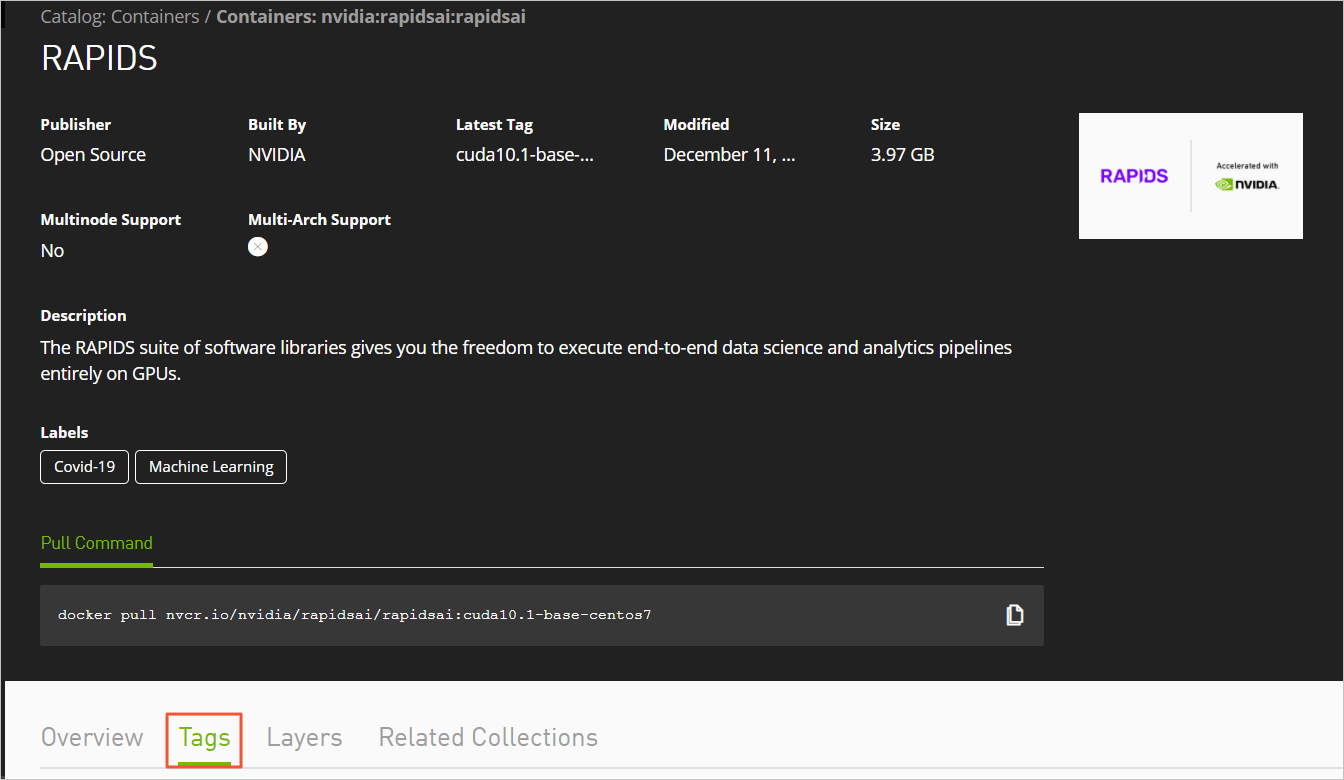
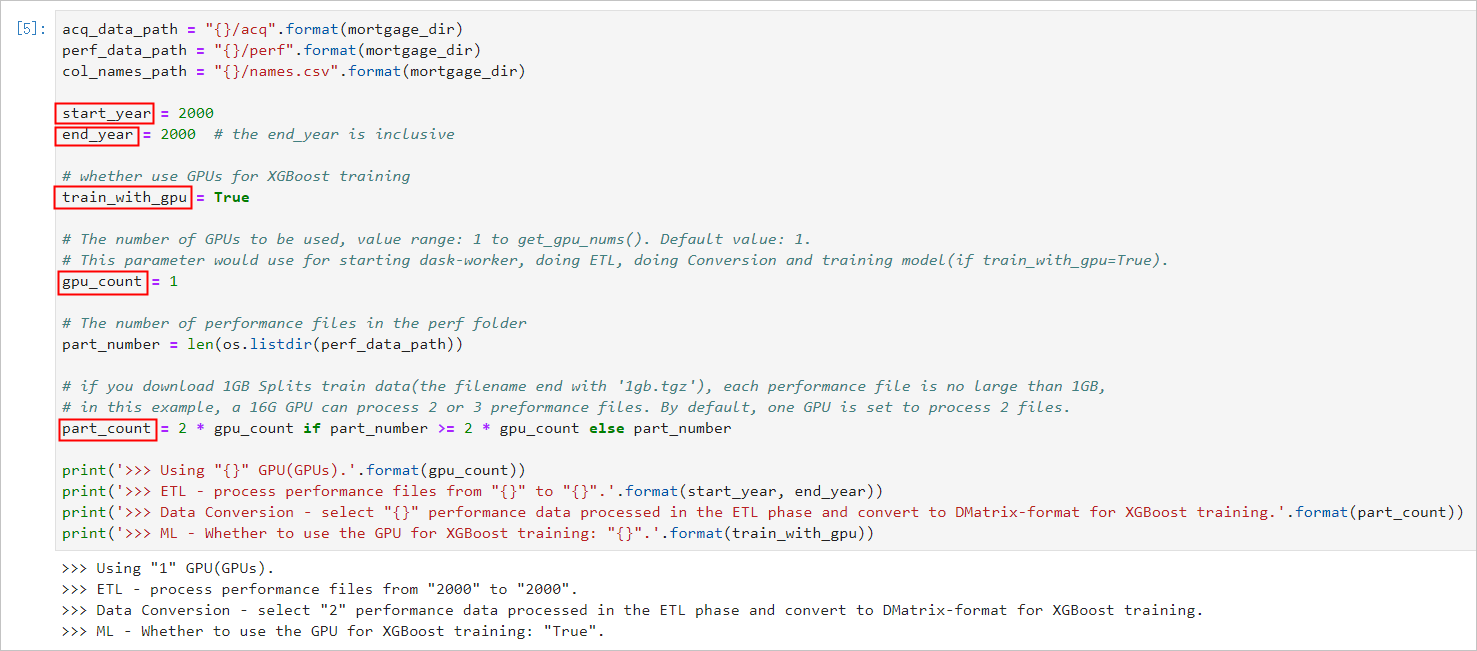
RAPIDS(全称Real-time Acceleration Platform for Integrated Data Science)是NVIDIA针对数据科学和机器学习推出的GPU加速库。更多信息,请参见RAPIDS网站。 RAPIDS预装镜像已经发布到阿里云镜像市场,创建GPU实例时,您可以在镜像市场中搜索NVIDIA RAPIDS并使用RAPIDS预装镜像。 说明 该RAPIDS预装镜像使用Ubuntu 16.04 64-bit操作系统。 NGC(全称NVIDIA GPU CLOUD)是NVIDIA推出的一套深度学习生态系统,供开发者免费访问深度学习和机器学习软件堆栈,快速搭建相应的开发环境。更多信息,请参见NGC网站,该网站提供了RAPIDS的Docker镜像,并预装了相关的开发环境。 JupyterLab是一套交互式的开发环境,帮助您高效地浏览、编辑和执行服务器上的代码文件。 Dask是一款轻量级大数据框架,可以提升并行计算效率。 本文提供了一套基于NVIDIA的RAPIDS Demo代码及数据集修改的示例代码,演示了在GPU实例上使用RAPIDS加速一个从ETL到ML Training端到端任务的过程。其中,ETL时使用RAPIDS的cuDF,ML Training时使用XGBoost。本文示例代码基于轻量级大数据框架Dask运行,为一套单机运行的代码。 NVIDIA官方RAPIDS Demo代码的更多信息,请参见Mortgage Demo。 如果您创建GPU实例时使用了RAPIDS预装镜像,只需运行RAPIDS Demo,从启动JupyterLab服务开始操作即可。具体操作,请参见启动JupyterLab服务。 如果您创建GPU实例时没有使用RAPIDS预装镜像,按照以下步骤使用RAPIDS加速机器学习任务: 完成以下操作,获取RAPIDS镜像下载命令: 登录NGC网站。 在页面左侧导航栏,选择。 在NVIDIA NGC: AI Development Catalog页面的搜索栏中,输入RAPIDS。 在搜索结果中,单击RAPIDS镜像。 获取docker pull命令。 本文示例代码基于RAPIDS 0.8版本镜像编写,因此在运行本示例代码时,使用Tag为0.8版本的镜像。实际操作时,请选择您匹配的版本。 单击Tags页签。 找到并复制Tag信息。本示例中,选择 返回页面顶部,复制Pull Command中的命令到文本编辑器,将镜像版本替换为对应的Tag信息,并保存。 本示例中,将 保存的docker pull命令用于下载RAPIDS镜像。关于如何下载RAPIDS镜像,请参见步骤三:部署RAPIDS环境。 完成以下操作,部署RAPIDS环境: 创建一台GPU实例。详细步骤请参见自定义购买实例。 参数配置说明如下: TCP 22 端口,用于SSH登录 TCP 8888端口,用于支持访问JupyterLab服务 TCP 8787端口、TCP 8786端口,用于支持访问Dask服务 实例:RAPIDS仅适用于特定的GPU型号(采用NVIDIA Pascal及以上架构),因此您需要选择GPU型号符合要求的实例规格,目前有gn6i、gn6v、gn5和gn5i,详细的GPU型号请参见实例规格族。建议您选择显存更大的gn6i、gn6v或gn5实例。本示例中,选用了显存为16 GB的GPU实例。 镜像:在镜像市场中搜索并使用 公网带宽:选择分配公网IPv4地址或者在实例创建成功后绑定EIP地址。具体操作,请参见弹性公网IP文档中的绑定ECS实例。 安全组:选择的安全组需要开放以下端口: 连接GPU实例。连接方式请参见连接方式介绍。 输入NGC APIKey后按回车键,登录NGC容器环境。 可选:运行nvidia-smi查看GPU型号、GPU驱动版本等GPU信息。 建议您了解GPU信息,预判规避潜在问题。例如,如果NGC的驱动版本太低,新Docker镜像版本可能会不支持。 运行docker pull命令下载RAPIDS镜像。 关于如何获取docker pull命令,请参见步骤二:获取RAPIDS镜像下载命令。 可选:查看下载的镜像。 建议您查看Docker镜像信息,确保下载了正确的镜像。 运行容器部署RAPIDS环境。 完成以下操作,运行RAPIDS Demo: 在GPU实例上下载数据集和Demo文件。 在GPU实例上启动JupyterLab服务。 推荐您直接使用以下命令启动JupyterLab服务。 说明 在GPU实例上使用命令启动JupyterLab服务时,需要使用root权限进行操作。 除使用命令外,您也可以执行脚本 您也可以连续按两次 打开浏览器(推荐使用Chrome浏览器),在地址栏输入 如果您在启动JupyterLab服务时设置了登录密码,会跳转到密码输入界面。 运行NoteBook代码。 该案例是一个抵押贷款回归的任务,更多信息,请参见代码执行过程。登录成功后,可以看到NoteBook代码包括以下内容: xgboost_E2E.ipynb文件: XGBoost Demo文件。双击文件可以查看文件详情,单击下图中的执行按钮可以逐步执行代码,每次执行一个Cell。 mortgage_2000_1gb.tgz文件:2000年的抵押贷款回归训练数据(1G分割的perf文件夹下的文件不会大于1 G,使用1 G分割的数据可以更有效的利用GPU显存)。 该案例基于XGBoost演示了数据预处理到训练的端到端的过程,主要分为三个阶段: ETL(Extract-Transform-Load):主要在GPU实例上进行。将业务系统的数据经过抽取、清洗转换之后加载到数据仓库。 Data Conversion:在GPU实例上进行。将在ETL阶段处理过的数据转换为用于XGBoost训练的DMatrix格式。 ML-Training:默认在GPU实例上进行。使用XGBoost训练梯度提升决策树 。 NoteBook代码的执行过程如下: 准备数据集。 本案例的Shell脚本会默认下载2000年的抵押贷款回归训练数据(mortgage_2000_1gb.tgz)。 设定相关参数。 参数名称 说明 start_year 指定选择训练数据的起始时间,ETL时会处理start_year到end_year之间的数据。 end_year 指定选择训练数据的结束时间,ETL时会处理start_year到end_year之间的数据。 train_with_gpu 是否使用GPU进行XGBoost模型训练,默认为True。 gpu_count 指定启动worker的数量,默认为1。您可以按需要设定参数值,但不能超出GPU实例的GPU数量。 part_count 指定用于模型训练的performance文件的数量,默认为2 * gpu_count。如果参数值过大,在Data Conversion阶段会报错超出GPU内存限制,错误信息会在NoteBook后台输出。 示例效果如下: 启动Dask服务。 代码会启动Dask Scheduler,并根据gpu_count参数启动worker用于ETL和模型训练。启动Dask服务后,您也可以通过Dask Dashboard直观地监控任务,打开方法请参见Dask Dashboard。 示例效果如下: 启动ETL。 ETL阶段会进行到表关联、分组、聚合、切片等操作,数据格式采用cuDF库的DataFrame格式(类似于pandas的DataFrame格式)。 示例效果如下: 启动Data Conversion。 将DataFrame格式的数据转换为用于XGBoost训练的DMatrix格式,每个worker处理一个DMatrix对象。 示例效果如下: 启动ML Training。 使用dask-xgboost启动模型训练,dask-xgboost负责多个dask worker间的通信协同工作,底层仍然调用xgboost执行模型训练。 示例效果如下: Dask Dashboard支持任务进度跟踪、任务性能问题识别和故障调试。 Dask服务启动后,在浏览器地址栏中访问 函数功能 函数名称 函数功能 函数名称 下载文件 def download_file_from_url(url, filename): 解压文件 def decompress_file(filename, path): 获取当前机器的GPU个数 def get_gpu_nums(): 管理GPU内存 def initialize_rmm_pool(): def initialize_rmm_no_pool(): def run_dask_task(func, **kwargs): 提交DASK任务 def process_quarter_gpu(year=2000, quarter=1, perf_file=""): def run_gpu_workflow(quarter=1, year=2000, perf_file="", **kwargs): 使用cuDF从CSV中加载数据 def gpu_load_performance_csv(performance_path, **kwargs): def gpu_load_acquisition_csv(acquisition_path, **kwargs): def gpu_load_names(**kwargs): 处理和提取训练数据的特征 def null_workaround(df, **kwargs): def create_ever_features(gdf, **kwargs): def join_ever_delinq_features(everdf_tmp, delinq_merge, **kwargs): def create_joined_df(gdf, everdf, **kwargs): def create_12_mon_features(joined_df, **kwargs): def combine_joined_12_mon(joined_df, testdf, **kwargs): def final_performance_delinquency(gdf, joined_df, **kwargs): def join_perf_acq_gdfs(perf, acq, **kwargs): def last_mile_cleaning(df, **kwargs):背景信息
操作步骤
步骤一:获取NGC API Key
步骤二:获取RAPIDS镜像下载命令
0.8-cuda10.0-runtime-ubuntu16.04-gcc5-py3.6。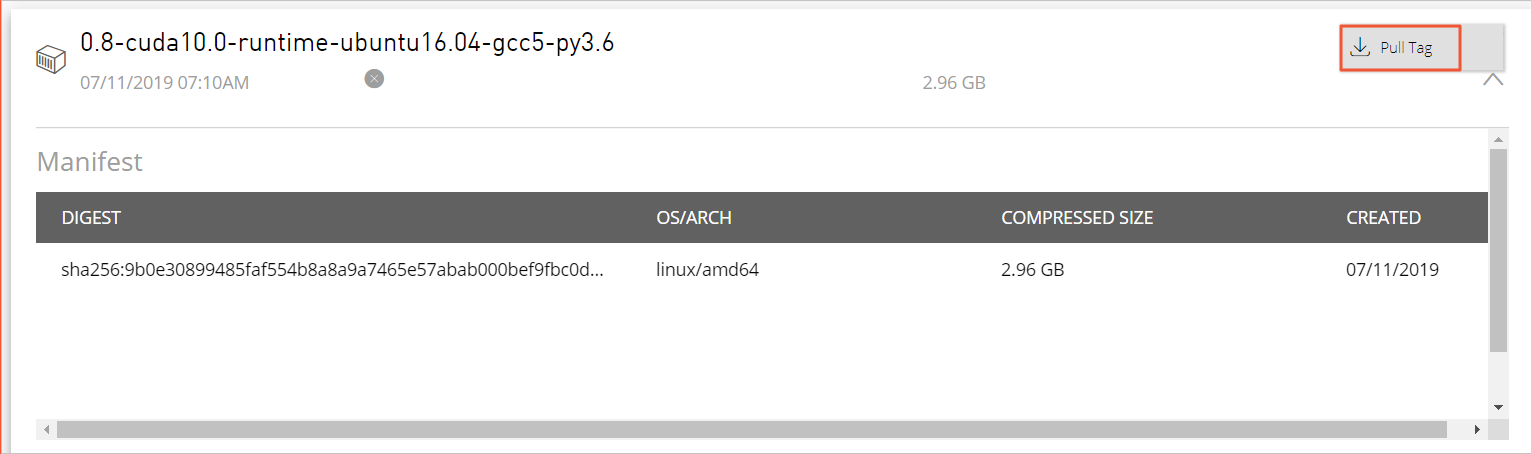
cuda9.2-runtime-ubuntu16.04替换为0.8-cuda10.0-runtime-ubuntu16.04-gcc5-py3.6。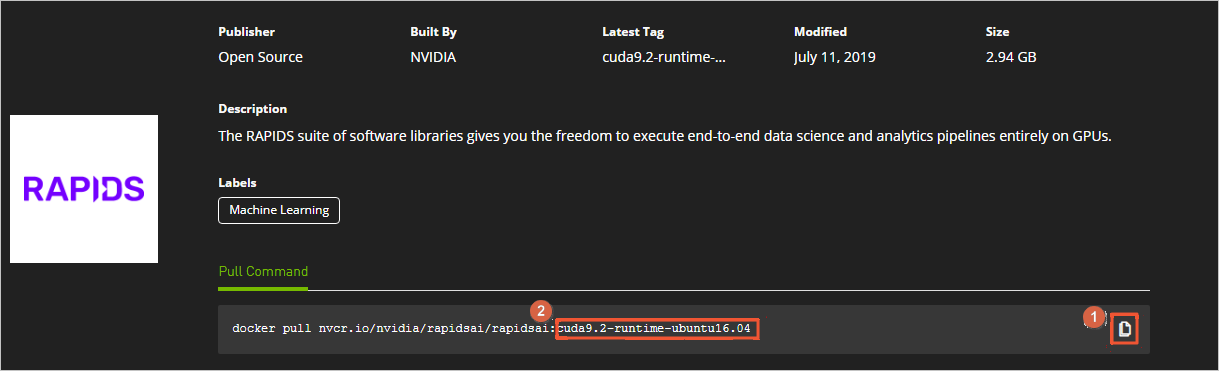
步骤三:部署RAPIDS环境
NVIDIA GPU Cloud VM Image。
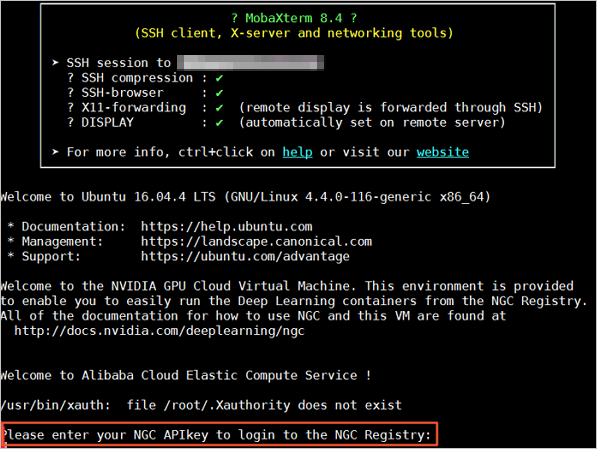
docker pull nvcr.io/nvidia/rapidsai/rapidsai:0.8-cuda10.0-runtime-ubuntu16.04-gcc5-py3.6
docker images
docker run --runtime=nvidia \ --rm -it \ -p 8888:8888 \ -p 8787:8787 \ -p 8786:8786 \ nvcr.io/nvidia/rapidsai/rapidsai:0.8-cuda10.0-runtime-ubuntu16.04-gcc5-py3.6
步骤四:运行RAPIDS Demo
# Get apt source address and download demos. source_address=$(curl http://100.100.100.200/latest/meta-data/source-address|head -n 1) source_address="${source_address}/opsx/ecs/linux/binary/machine_learning/" cd /rapids wget $source_address/rapids_notebooks_v0.8.tar.gz tar -xzvf rapids_notebooks_v0.8.tar.gz cd /rapids/rapids_notebooks_v0.8/xgboost wget $source_address/data/mortgage/mortgage_2000_1gb.tgz# Run the following command to start JupyterLab and set the password. cd /rapids/rapids_notebooks_v0.8/xgboost jupyter-lab --allow-root --ip=0.0.0.0 --no-browser --NotebookApp.token='YOUR LOGON PASSWORD' # Exit JupyterLab. sh ../utils/stop-jupyter.sh
sh ../utils/start-jupyter.sh启动jupyter-lab,此时无法设置登录密码。Ctrl+C退出JupyterLab服务。http://您的GPU实例IP地址:8888远程访问JupyterLab。
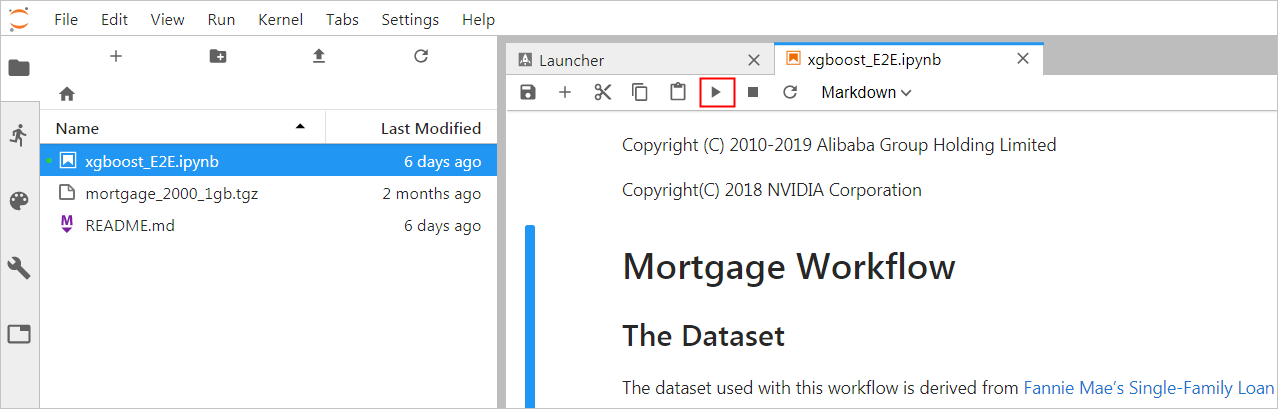
代码执行过程
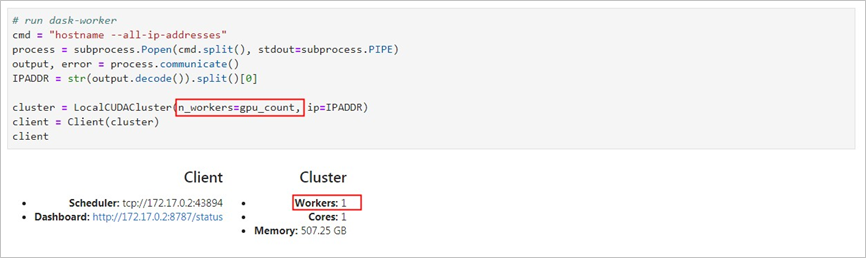
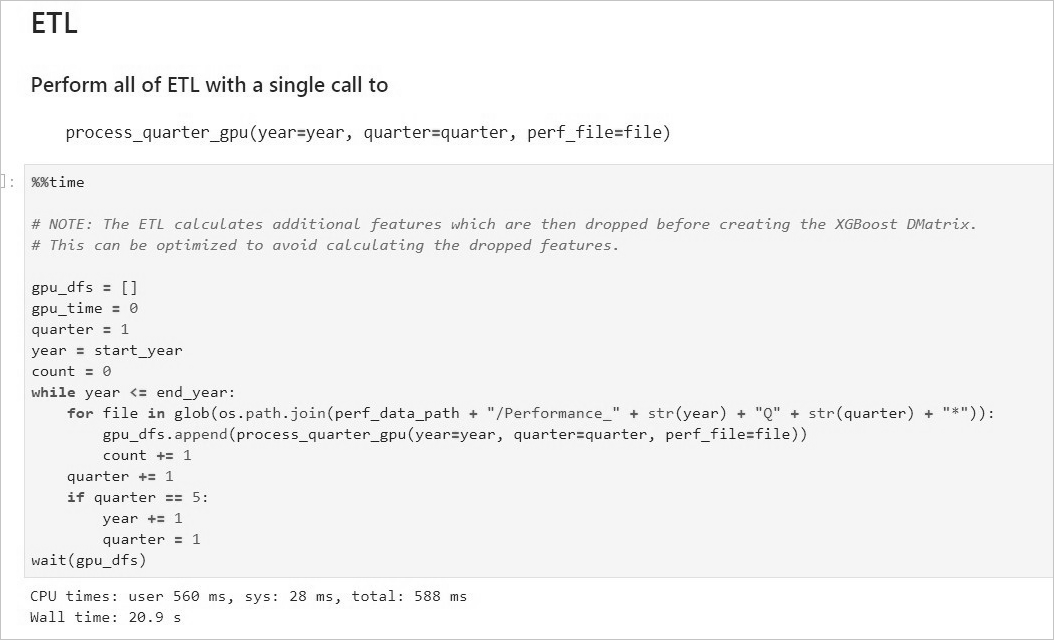
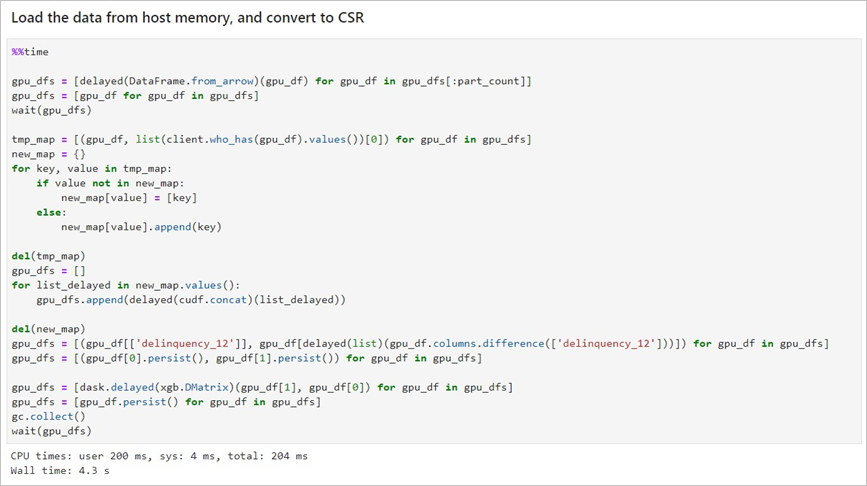
Dask Dashboard
http://您的GPU实例IP地址:8787/status即可进入Dashboard主界面。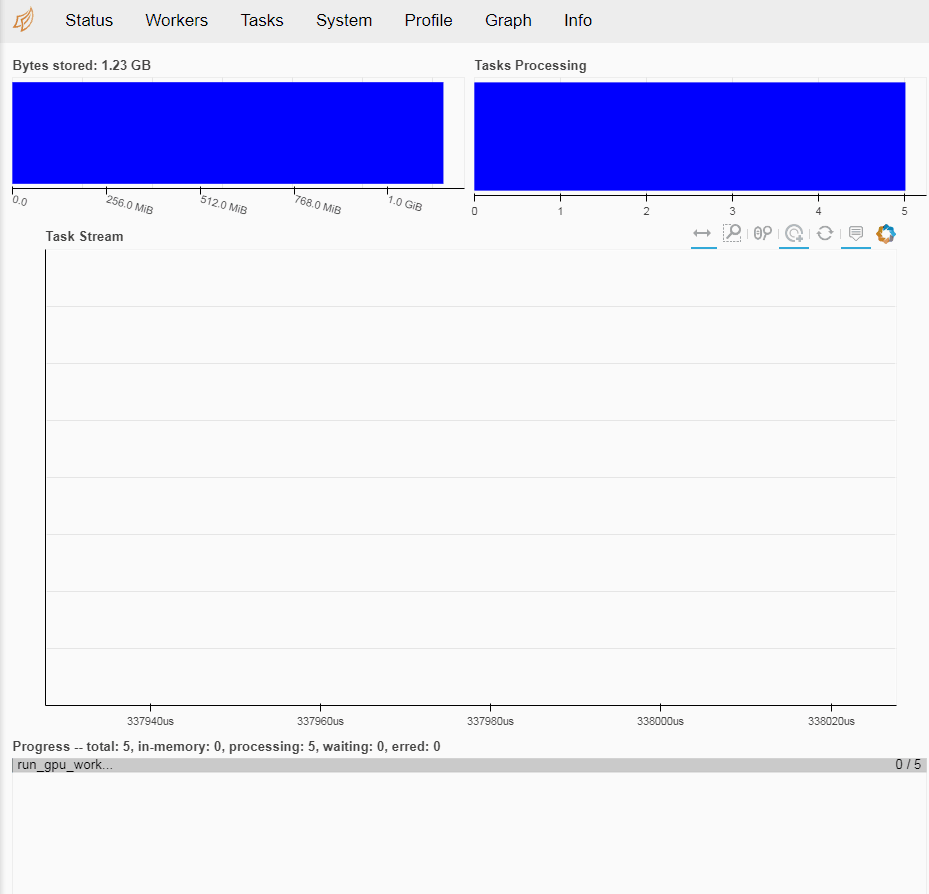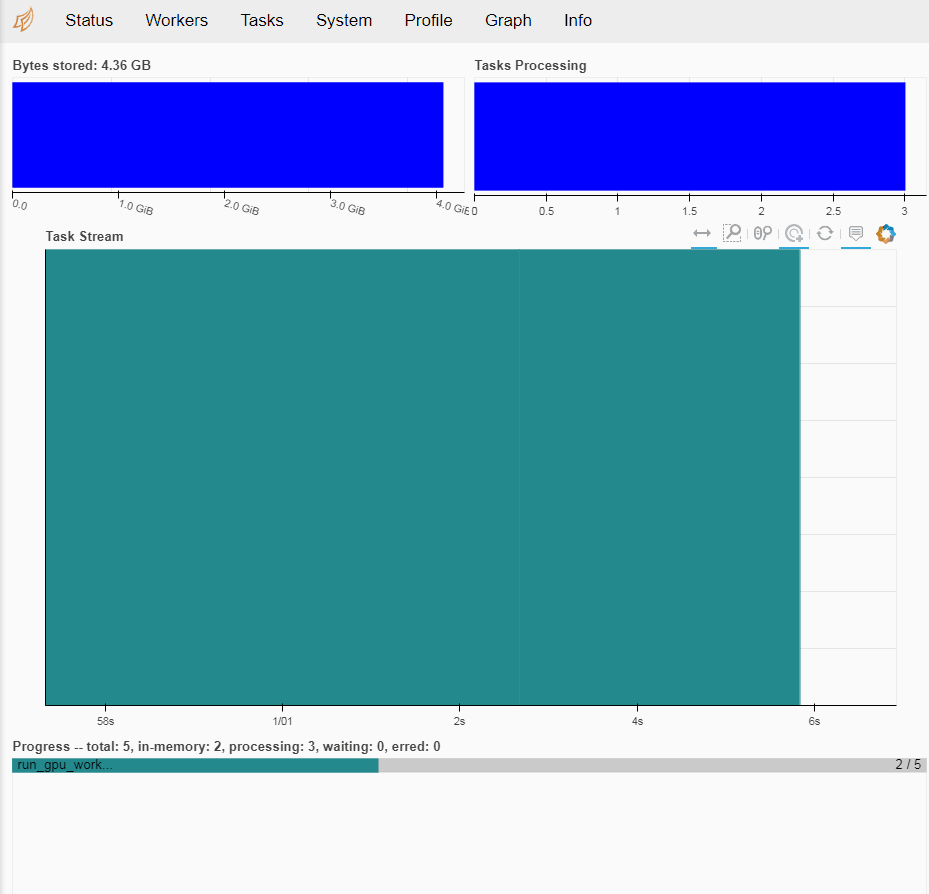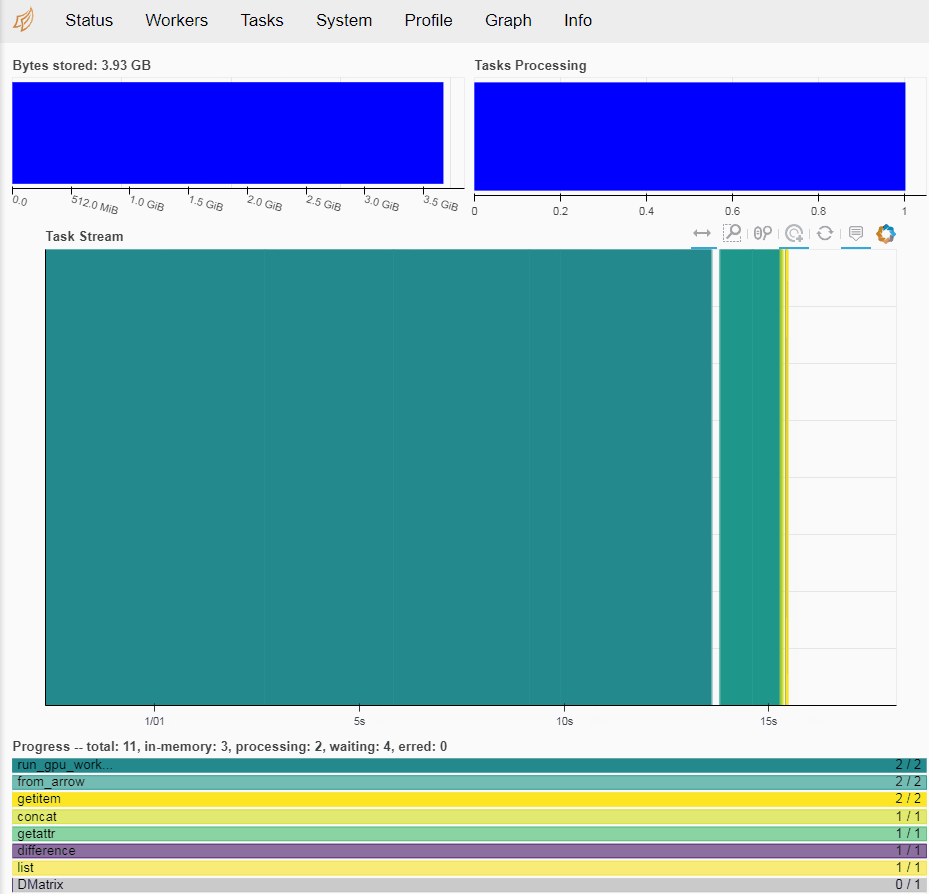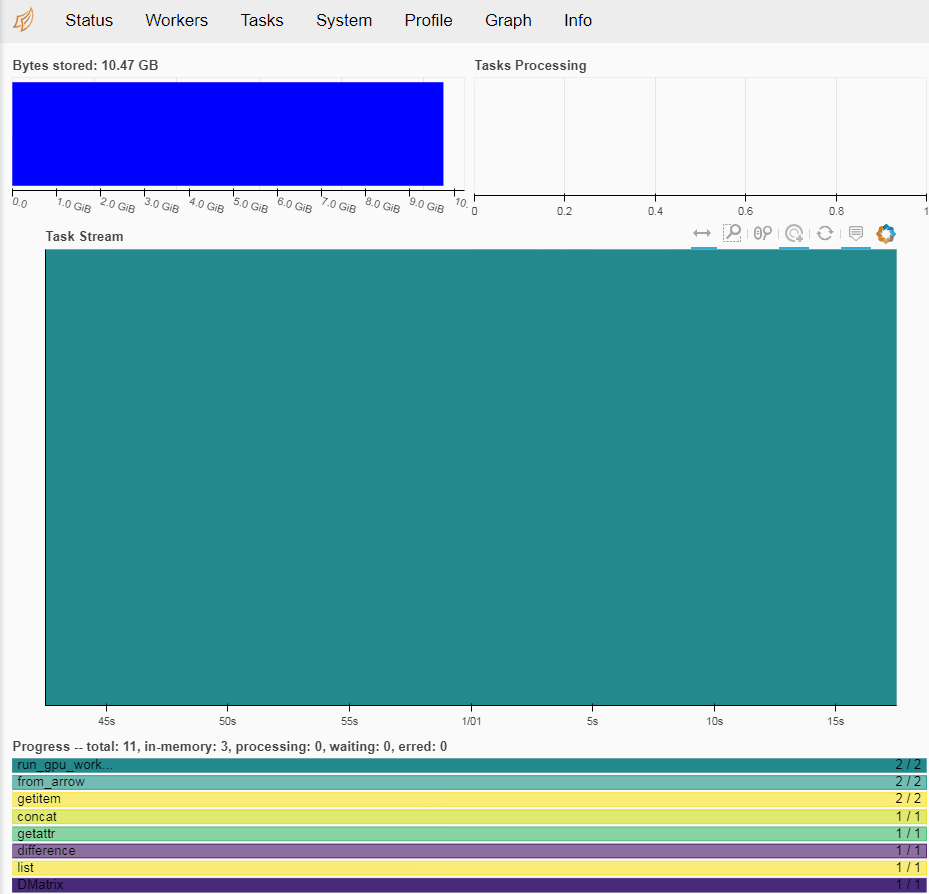
相关函数


