使用cGPU服务可以隔离GPU资源,实现多个容器共用一张GPU卡。该服务作为阿里云容器服务Kubernetes版ACK(Container Service for Kubernetes)的组件对外提供服务,应用于高性能计算能力的场景,例如机器学习、深度学习、科学计算等,方便您更高效地利用GPU资源,以加速计算任务。本文介绍如何通过安装并使用cGPU服务。
说明
cGPU服务的隔离功能不支持以UVM的方式(即调用CUDA API cudaMallocManaged())申请显存,请您使用其他方式申请显存,例如调用cudaMalloc()等。更多信息,请参见NVIDIA官方文档。
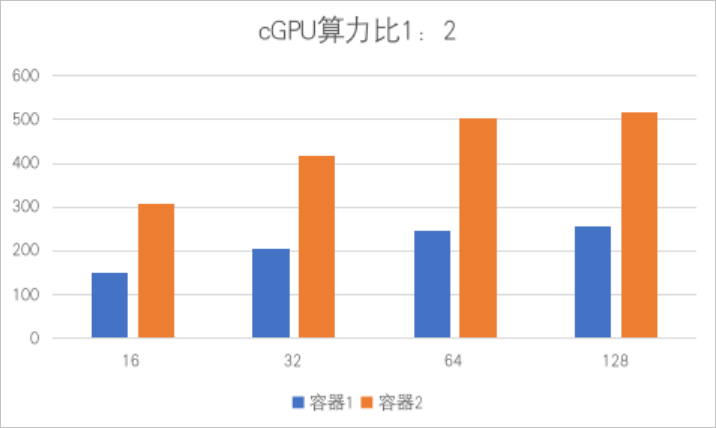
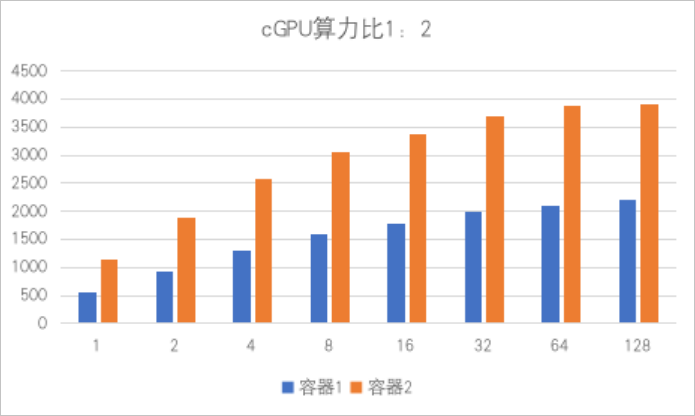
在进行本操作前,请确保GPU实例满足以下要求: GPU实例规格为gn7i、gn6i、gn6v、gn6e、gn5i、gn5、ebmgn7i、ebmgn6i、ebmgn7e、ebmgn6e、ebmgn7ex或sccgn7ex。 GPU实例操作系统为CentOS、Ubuntu或Alibaba Cloud Linux。 GPU实例已安装Tesla 418.87.01或更高版本的驱动。 GPU实例已安装Docker 19.03.5或更高版本。 无论您是企业认证用户还是个人实名认证用户,推荐您通过ACK的Docker运行时环境安装和使用cGPU服务。 重要 安装1.5.7版本的cGPU组件,可能会导致cGPU内核驱动出现死锁现象(即并发执行的进程互相牵制),从而导致Linux Kernel Panic(即内核错误)问题,建议您安装1.5.8及以上版本的cGPU,或将低版本cGPU逐步升级到1.5.8及以上版本,避免在新业务上出现内核错误问题。 创建集群。 具体操作,请参见创建ACK托管集群。 在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。 在云原生AI套件页面,单击一键部署。 在基础能力区域,选中调度策略扩展(批量任务调度、GPU共享、GPU拓扑感知)。 单击页面底部的部署云原生AI套件。 组件安装成功后,在云原生AI套件页面的组件列表中能看到已安装的共享GPU组件ack-ai-installer。 本文以ecs.gn6i-c4g1.xlarge为例演示2个容器共用1张显卡。 执行以下命令,创建容器并设置容器内可见的显存。 本示例中,设置 说明 该命令以使用TensorFlow镜像 gpu_test1:分配6 GiB显存。 gpu_test2:分配8 GiB显存。 执行以下命令,查看容器的显存等GPU信息。 以gpu_test1为例,容器gpu_test1中可见的显存为6043 MiB,如下图所示: cGPU服务运行时会在/proc/cgpu_km下生成并自动管理多个procfs节点,您可以通过procfs节点查看和配置cGPU服务相关的信息。 执行以下命令,查看procfs节点信息。 执行结果如下所示: 执行以下命令,查看GPU实例的显卡目录内容。 本示例中,以显卡0为例。 执行结果如下所示: 执行以下命令,查看容器对应的目录内容。 本示例中,以012b2edccd7a容器为例。 执行结果如下所示: (可选)执行以下命令,配置cGPU服务。 了解procfs节点的用途后,您可以在GPU实例中执行命令进行切换调度策略、修改权重等操作,示例命令如下表所示。 命令 效果 echo 2 > /proc/cgpu_km/0/policy 将调度策略切换为权重抢占调度。 cat /proc/cgpu_km/0/free_weight 查看显卡上可用的权重。如果 cat /proc/cgpu_km/0/$dockerid/weight 查看指定容器的权重。 echo 4 > /proc/cgpu_km/0/$dockerid/weight 修改容器获取GPU算力的权重。 您可以通过cgpu-smi工具查看cGPU容器的相关信息,包括容器ID、GPU利用率、算力限制、使用的显存以及分配显存的总量等信息。 说明 cgpu-smi是cGPU的监控示例。部署k8s时,您可以参考或使用cgpu-smi的示例做二次开发集成。 cgpu-smi的监控展示信息如下所示: 升级cGPU服务 卸载cGPU服务 升级cGPU服务支持冷升级和热升级两种方式。 冷升级 Docker未使用cGPU服务的情况下,采用冷升级方式升级cGPU服务,操作步骤如下: 执行以下命令,关闭所有运行中的容器。 执行以下命令,升级cGPU服务至最新版本。 热升级 Docker使用cGPU服务的情况下,可以采用热升级方式升级cGPU内核驱动,但是对于升级的版本有一定限制。 如需任何协助,请联系阿里云售后技术团队。 cGPU服务算力调度示例 cGPU服务多卡划分示例 cGPU服务加载cgpu_km的模块时,会按照容器最大数量(max_inst)为每张显卡设置时间片(X ms),用于为容器分配GPU算力,本示例中以Slice 1、Slice 2或Slice N表示。使用不同调度策略时的调度示例如下所示。 平均调度(policy=0) 在创建容器时,为容器分配时间片。cGPU服务会从Slice 1时间片开始调度,提交任务到物理GPU,并执行一个时间片(X ms)的时间,然后切换到下一个时间片。每个容器获得的算力相同,都为 抢占调度(policy=1) 在创建容器时,为容器分配时间片。cGPU服务会从Slice 1开始调度,但如果没有使用某个容器,或者容器内没有进程打开GPU设备,则跳过调度,切换到下一个时间片。 示例如下: 只创建一个容器Docker 1,获得Slice 1时间片,在Docker 1中运行2个TensorFlow进程,此时Docker 1最大获得整个物理GPU的算力。 再创建一个容器Docker 2,获得Slice 2时间片。如果Docker 2内没有进程打开GPU设备,调度时会跳过Docker 2的时间片Slice 2。 当Docker 2有进程打开GPU设备时,Slice 1和Slice 2都加入调度,Docker 1和Docker 2最大分别获得1/2物理GPU的算力,如下所示。 权重抢占调度(policy=2) 如果在创建容器时设置ALIYUN_COM_GPU_SCHD_WEIGHT大于1,则自动使用权重抢占调度。cGPU服务按照容器数量(max_inst)将物理GPU算力划分成max_inst份,但如果ALIYUN_COM_GPU_SCHD_WEIGHT大于1,cGPU服务会将多个时间片组合成一个更大的时间片分配给容器。 设置示例如下: 调度效果如下: 权重抢占调度限制了容器使用GPU算力的理论最大值。但对算力很强的显卡(例如NVIDIA V100显卡),如果显存使用较少,在一个时间片内即可完成计算任务。此时如果m:n值设置为8:4,则剩余时间片内GPU算力会闲置,限制基本失效。 如果只有Docker 1运行, Docker 1抢占整个物理GPU的算力。 如果Docker 1和Docker 2同时运行,Docker 1和Docker 2获得的理论算力比例是m:n。和抢占调度不同的是,即使Docker 2中没有GPU进程也会占用n个时间片的时间。 说明 m:n设置为2:1和8:4时的运行表现存在差别。在1秒内切换时间片的次数,前者是后者的4倍。 Docker 1:ALIYUN_COM_GPU_SCHD_WEIGHT=m Docker 2:ALIYUN_COM_GPU_SCHD_WEIGHT=n 固定算力调度(policy=3) 您可以通过指定ALIYUN_COM_GPU_SCHD_WEIGHT和max_inst的占比,固定算力的百分比。 算力弱调度(policy=4) 在创建容器时,为容器分配时间片,隔离性弱于抢占调度。更多信息,请参见抢占调度(policy=1)。 原生调度(policy=5) 只用来做显存的隔离。原生调度表示NVIDIA GPU驱动本身的调度方式。 算力调度策略支持阿里云所有的异构GPU实例,以及GPU实例所配备的NVIDIA显卡,其型号包含Tesla P4、Tesla P100、Tesla T4、Tesla V100、Tesla A10。以下测试项使用2个容器共享一台单卡A10的GPU实例,并将2个容器的算力比设置为1:2,将显存均分,每个容器的显存为12 G。 说明 以下性能测试结果数据为实验室数据,仅供参考。 测试项1: 在基于TensorFlow框架训练的ResNet50模型、精度为FP16的场景下,测试不同batch_size下的性能数据比较。结果如下所示: 框架 模型 batch_size 精度 images/sec(容器1) images/sec(容器2) TensorFlow ResNet50 16 FP16 151 307 TensorFlow ResNet50 32 FP16 204 418 TensorFlow ResNet50 64 FP16 247 503 TensorFlow ResNet50 128 FP16 257 516 测试项2:在基于TensorRT框架训练的ResNet50模型、精度为FP16的场景下,测试不同batch_size下的性能数据比较。结果如下所示: 框架 模型 batch_size 精度 images/sec(容器1) images/sec(容器2) TensorRT ResNet50 1 FP16 568.05 1132.08 TensorRT ResNet50 2 FP16 940.36 1884.12 TensorRT ResNet50 4 FP16 1304.03 2571.91 TensorRT ResNet50 8 FP16 1586.87 3055.66 TensorRT ResNet50 16 FP16 1783.91 3381.72 TensorRT ResNet50 32 FP16 1989.28 3695.88 TensorRT ResNet50 64 FP16 2105.81 3889.35 TensorRT ResNet50 128 FP16 2205.25 3901.94前提条件
安装cGPU服务
使用cGPU服务
运行cGPU服务
ALIYUN_COM_GPU_MEM_CONTAINER和ALIYUN_COM_GPU_MEM_DEV环境变量指定显卡的总显存和容器内可见的显存。例如创建2个容器:nvcr.io/nvidia/tensorflow:19.10-py3为例,请根据实际情况更换为您自己的容器镜像。使用TensorFlow镜像搭建TensorFlow深度学习框架的操作,请参见部署NGC环境构建深度学习开发环境。sudo docker run -d -t --gpus all --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --name gpu_test1 -v /mnt:/mnt -e ALIYUN_COM_GPU_MEM_CONTAINER=6 -e ALIYUN_COM_GPU_MEM_DEV=15 nvcr.io/nvidia/tensorflow:19.10-py3
sudo docker run -d -t --gpus all --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --name gpu_test2 -v /mnt:/mnt -e ALIYUN_COM_GPU_MEM_CONTAINER=8 -e ALIYUN_COM_GPU_MEM_DEV=15 nvcr.io/nvidia/tensorflow:19.10-py3
sudo docker exec -i gpu_test1 nvidia-smi

通过procfs节点查看cGPU服务
ls /proc/cgpu_km/

ls /proc/cgpu_km/0

ls /proc/cgpu_km/0/012b2edccd7a

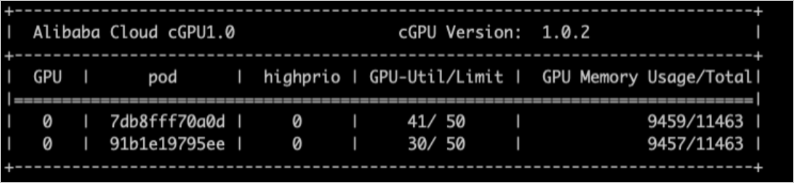
free_weight=0,新创建容器的权重值为0,该容器不能获取GPU算力,不能用于运行需要GPU算力的应用。通过cgpu-smi工具查看cGPU容器
升级或卸载cGPU服务
sudo docker stop $(docker ps -a | awk '{ print $1}' | tail -n +2)sudo sh upgrade.sh
cGPU服务使用示例
1/max_inst,如下所示。