Hadoop 工具依赖 Hadoop-2.7.2 及以上版本,实现了以腾讯云对象存储(Cloud Object Storage,COS)作为底层存储文件系统运行上层计算任务的功能。启动 Hadoop 集群主要有单机、伪分布式和完全分布式等三种模式,本文主要以 Hadoop-2.7.4 版本为例进行 Hadoop 完全分布式环境搭建及 wordcount 简单测试介绍。
1. 准备若干台机器。
2. 安装配置系统,可前往 CentOS 官网 下载安装。本文使用 CentOS 7.3.1611系统版本。
3. 安装 Java 环境,具体操作请参见 Java 安装与配置。
4. 安装 Hadoop 可用包:Apache Hadoop Releases Download。
使用ifconfig -a查看各台机器的 IP,相互使用 ping 命令检查 ,看是否可以 ping 通,同时记录每台机器的 IP。
分别给机器设置相应hostname,如"master"、"slave*"等。hostnamectl set-hostname master
编辑内容:202.xxx.xxx.xxx master202.xxx.xxx.xxx slave1202.xxx.xxx.xxx slave2202.xxx.xxx.xxx slave3# IP 地址替换为真实 IP
上传 JDK 安装包(如jdk-8u144-linux-x64.tar.gz)到root根目录。mkdir /usr/javatar -zxvf jdk-8u144-linux-x64.tar.gz -C /usr/java/rm -rf jdk-8u144-linux-x64.tar.gz
编辑内容:
export JAVA_HOME=/usr/java/jdk1.8.0_144export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
保存文件后,使/etc/profile生效,执行以下命令:
source /etc/profile # 使配置文件生效java -version # 查看 java 版本
分别在各个主机上检查 SSH 服务状态:
systemctl status sshd.service # 检查 SSH 服务状态yum install openssh-server openssh-clients # 安装 SSH 服务,如果已安装,则不用执行该步骤systemctl start sshd.service # 启动 SSH 服务,如果已安装,则不用执行该步骤
分别在各个主机上生成密钥:
ssh-keygen -t rsa # 生成密钥
在 slave1 上:
cp ~/.ssh/id_rsa.pub ~/.ssh/slave1.id_rsa.pubscp ~/.ssh/slave1.id_rsa.pub master:~/.ssh
在 slave2 上:
cp ~/.ssh/id_rsa.pub ~/.ssh/slave2.id_rsa.pubscp ~/.ssh/slave2.id_rsa.pub master:~/.ssh
依此类推... 在 master 上:
cd ~/.sshcat id_rsa.pub >> authorized_keyscat slave1.id_rsa.pub >>authorized_keyscat slave2.id_rsa.pub >>authorized_keysscp authorized_keys slave1:~/.sshscp authorized_keys slave2:~/.sshscp authorized_keys slave3:~/.ssh
上传 hadoop 安装包(如hadoop-2.7.4.tar.gz)到root根目录。
tar -zxvf hadoop-2.7.4.tar.gz -C /usrrm -rf hadoop-2.7.4.tar.gzmkdir /usr/hadoop-2.7.4/tmpmkdir /usr/hadoop-2.7.4/logsmkdir /usr/hadoop-2.7.4/hdfmkdir /usr/hadoop-2.7.4/hdf/datamkdir /usr/hadoop-2.7.4/hdf/name
进入hadoop-2.7.4/etc/hadoop目录下,进行下一步操作。
1. 修改hadoop-env.sh文件,增加如下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_144
若 SSH 端口不是默认的22,可在hadoop-env.sh文件里修改:
export HADOOP_SSH_OPTS="-p 1234"
2. 修改 yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_144
3. 修改slaves配置内容:
删除:localhost添加:slave1slave2slave3
4. 修改core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/hadoop-2.7.4/tmp</value> </property></configuration>
5. 修改hdfs-site.xml
<configuration> <property> <name>dfs.datanode.data.dir</name> <value>/usr/hadoop-2.7.4/hdf/data</value> <final>true</final> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/hadoop-2.7.4/hdf/name</value> <final>true</final> </property></configuration>
6. 将mapred-site.xml.template拷贝一份出来命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
7. 修改mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property></configuration>
8. 修改yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property></configuration>
9. 各个主机之间复制 Hadoop
scp -r /usr/hadoop-2.7.4 slave1:/usrscp -r /usr/hadoop-2.7.4 slave2:/usrscp -r /usr/hadoop-2.7.4 slave3:/usr
10. 各个主机配置 Hadoop 环境变量
打开配置文件:
vi /etc/profile
编辑内容:
export HADOOP_HOME=/usr/hadoop-2.7.4export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexport HADOOP_LOG_DIR=/usr/hadoop-2.7.4/logsexport YARN_LOG_DIR=$HADOOP_LOG_DIR
使配置文件生效:
source /etc/profile
1. 格式化 namenode
cd /usr/hadoop-2.7.4/sbinhdfs namenode -format
2. 启动
cd /usr/hadoop-2.7.4/sbinstart-all.sh
3. 检查进程 master 主机包含 ResourceManager、SecondaryNameNode、NameNode 等,则表示启动成功,例如:
2212 ResourceManager2484 Jps1917 NameNode2078 SecondaryNameNode
各个 slave 主机包含 DataNode、NodeManager 等,则表示启用成功,例如:
17153 DataNode17334 Jps17241 NodeManager
由于 Hadoop 自带 wordcount 例程,所以可以直接调用。在启动 Hadoop 之后,我们可以通过以下命令来对 HDFS 中的文件进行操作:
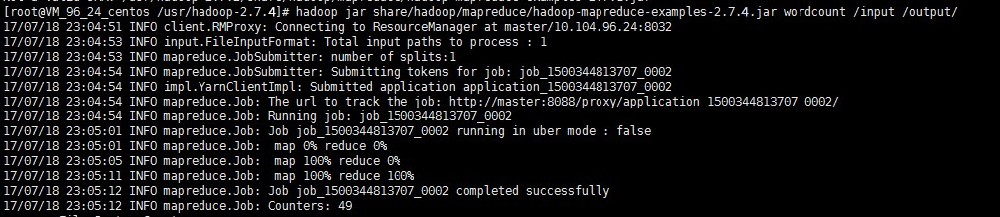
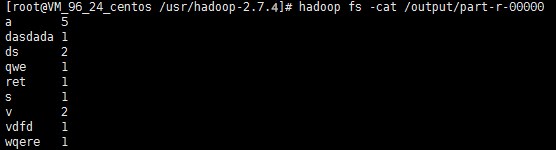
hadoop fs -mkdir /inputhadoop fs -put input.txt /inputhadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /input /output/
出现如上图结果就说明 Hadoop 安装已经成功了。
说明:
单机模式与伪分布式模式的操作方法的详细过程,请参见官网文档 Hadoop入门。